We can make two kinds of predictions from our model [Faraway (2002); Section 3.5]:
predictions about the “average” (“if we have some set of covariates, what is the average response given those covariates?”) – mean future predictions
predictions about specific situation (“we have some set of covariates, what is it’s prediction”) – predictions of future observations
In both cases the mean effect will be the same (so we can simply use the output from predict(model)but there are differences in how to calculate the uncertainty. In the latter case we need to include the additional variance from the error term in the model (usually denoted \(\epsilon\)). We call this second case a prediction interval.
Thinking about the normal response case (ignoring link functions etc for now), if we can write down the linear predictor of our model as \(\boldsymbol{X}\boldsymbol{\beta}\), we want \(\text{Var}(\boldsymbol{X}\boldsymbol{\beta})\) in case 1. above. For case 2. we have the prediction as \(\boldsymbol{X}\boldsymbol{\beta} + \epsilon\). \(\mathbf{E}(\epsilon) = 0\), so we ignore this for the mean effect, but we need to take \(\epsilon\) into account.
More generally, we want to take into account uncertainty from the various hyperparameters of the response distribution, like scale, shape etc.
It’s simplest to show this via posterior simulation, so that’s what is used here.
A general algorithm
We start with the posterior simulation template, so first let’s define some terms. \(\mathbf{X}_{p}\) is the matrix that maps parameters to their predictions on the linear predictor scale (the “\(L_p\) matrix” or “projection matrix”). \(\boldsymbol{\beta}\) is the vector of parameters from our fitted model and \(\mathbf{V}_{\hat{\boldsymbol{\beta}}}\) is its corresponding variance-covariance matrix. It’s also worth remembering that \(\boldsymbol{\beta}\) is approximately normally distributed (it’s exact for normal response), so we can use the multivariate normal distribution to generate \(\boldsymbol{\beta}\)s that are consistent with our model.
Regular posterior simulation is as follows:
For \(b=1,\ldots,B\):
Simulate from \(N(\hat{\boldsymbol{\beta}},\mathbf{V}_{\hat{\boldsymbol{\beta}}})\), to obtain \(\boldsymbol{\beta}_{b}\).
Generate a random deviate from the response family with mean \(Y_b^*\) and other (hyper)parameters from the fitted model (scale, etc) to obtain \(Y^\dagger_b\).
Calculate the empirical variance or percentiles of the \(Y_b^\dagger\)s.
Our addition here is at point 3, generating random deviates from the response family. In the normal case, this just corresponds to generating using rnorm, mean generated from the simulated predictions and the variance using the estimated scale parameter (model$scale). For other distributions it may involve fewer scale parameters (e.g., Poisson) or more (e.g., Gamma).
For the first example, we’ll simulate some normally-distributed data using the gamSim function in mgcv, but only use one predictor, for simplicity.
library(mgcv)
Loading required package: nlme
This is mgcv 1.9-4. For overview type '?mgcv'.
## simulate some data...set.seed(8)dat <-gamSim()
Gu & Wahba 4 term additive model
# just want one predictor here to make y just f2 + noisedat$y <- dat$f2 +rnorm(400, 0, 1)
We can then fit an extremely boring model to this data:
## fit smooth model to x, y data...b <-gam(y~s(x2,k=20), method="REML", data=dat)
Now to the central bit of the problem
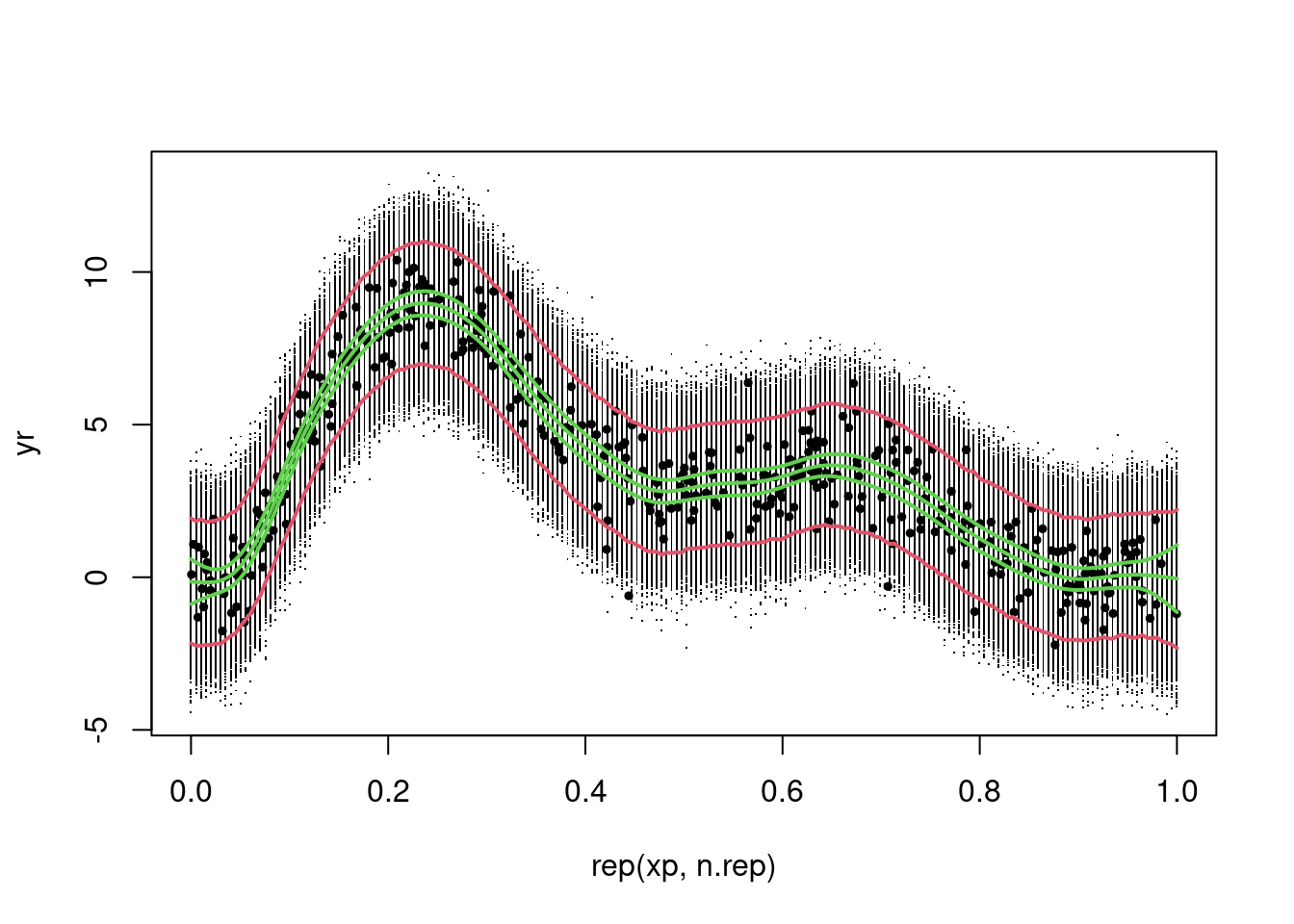
## simulate replicate beta vectors from posterior...n.rep <-10000br <-rmvn(n.rep, coef(b), vcov(b))## turn these into replicate smoothsxp <-seq(0, 1, length.out=200)# this is the "Lp matrix" which maps the coefficients to the predictors# you can think of it like the design matrix but for the predictionsXp <-predict(b, newdata=data.frame(x2=xp), type="lpmatrix")# note that we should apply the link function here if we have one# this is now a matrix with n.rep replicate smooths over length(xp) locationsfv <- Xp%*%t(br)# now simulate from normal deviates with mean as in fv# and estimated scale...yr <-matrix(rnorm(length(fv), fv, b$scale), nrow(fv), ncol(fv))
now make some plots
# plot the replicates in yrplot(rep(xp, n.rep), yr, pch=".")# and the data we used to fit the modelpoints(dat$x2, dat$y, pch=19, cex=.5)# compute 95% prediction interval# since yr is a matrix where each row is a data location along x2 and# each column is a replicate we want the quantiles over the rows, summarizing# the replicates each timePI <-apply(yr, 1, quantile, prob=c(.025,0.975))# the result has the 2.5% bound in the first row and the 97.5% bound# in the second# we can then plot those two boundslines(xp, PI[1,], col=2, lwd=2)lines(xp, PI[2,], col=2, lwd=2)# and optionally add the confidence interval for comparison...pred <-predict(b, newdata=data.frame(x2=xp), se=TRUE)lines(xp, pred$fit, col=3, lwd=2)u.ci <- pred$fit +2*pred$se.fitl.ci <- pred$fit -2*pred$se.fitlines(xp, u.ci, col=3, lwd=2)lines(xp, l.ci, col=3, lwd=2)
Example 2 - Tweedie response with multiple smooths
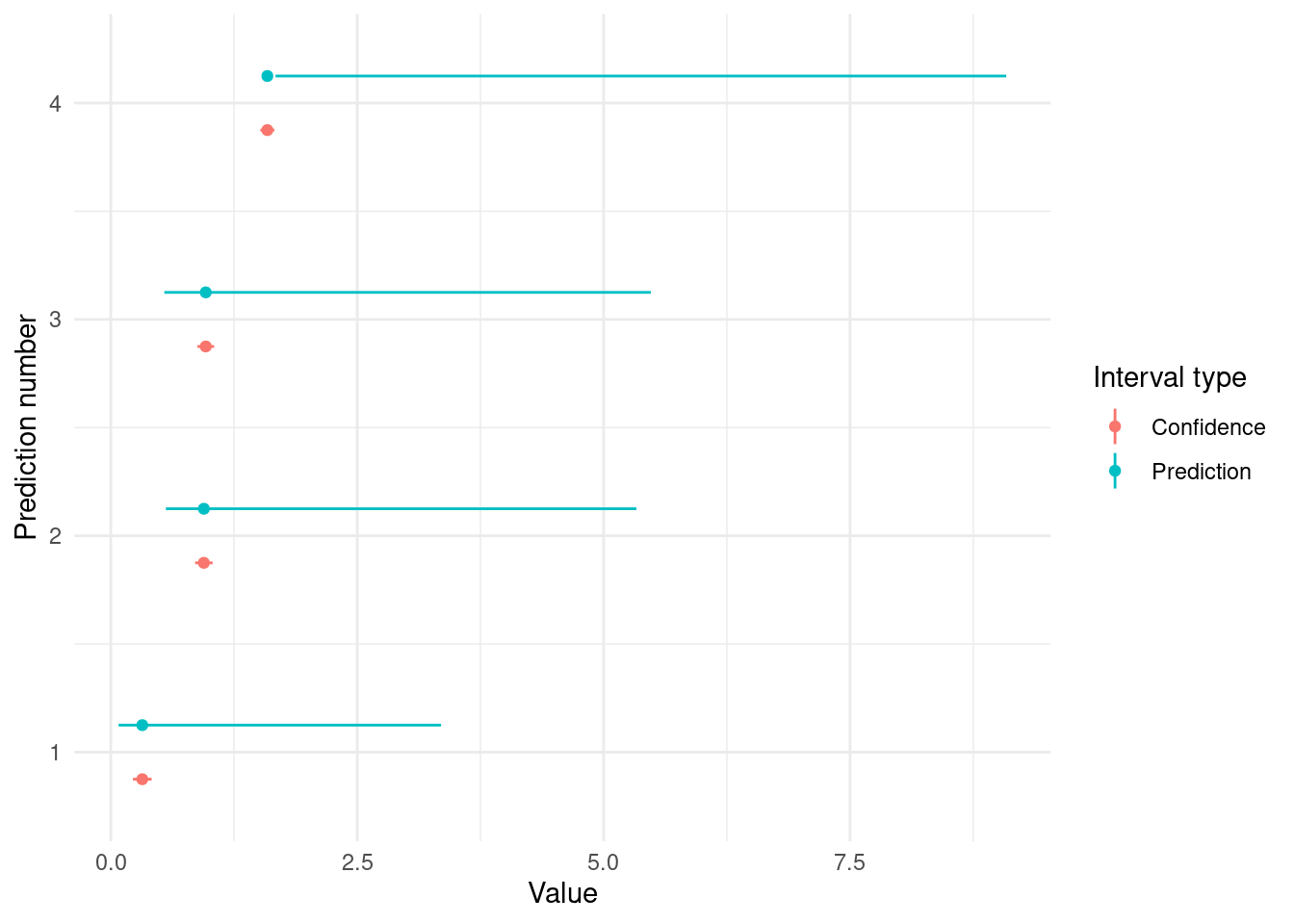
In this case we’re not going to plot smooths, but look at the prediction interval around a couple of predictions, to show that this method is very flexible.
library(mgcv)# taken from ?mgcv::twset.seed(3)n <-400## Simulate data...dat <-gamSim(1, n=n, dist="poisson", scale=.2)
Gu & Wahba 4 term additive model
# using 2 terms to create the responsedat$y <-rTweedie(exp(dat$x2 + dat$x1), p=1.3, phi=.5)
We can then fit an extremely boring model to this data:
b2 <-gam(y~s(x2)+s(x1), family=tw(), data=dat)
## simulate replicate beta vectors from posterior...n.rep <-10000br <-rmvn(n.rep, coef(b2), vcov(b2))## turn these into replicate smooths# here our prediction grid includes all variables, all of which are# over 0,1xp <-c(0.2, 0.8)xp <-expand.grid(x2=xp, x1=xp)# build the Lp matrixXp <-predict(b2, newdata=xp, type="lpmatrix")# this is now a matrix with n.rep replicate smooths over length(xp)# locations. Exponentiate to put on the response scale.fv <-exp(Xp%*%t(br))# now simulate from Tweedie deviates with mean exp(fv) (log link!),# scale and power parameter from the modelyr <-matrix(rTweedie(fv, phi=b2$scale, p=b2$family$getTheta(TRUE)),nrow(fv), ncol(fv))